
Research Report
A MUSIC-THEORY DRIVEN EMOTION-RESPONSIVE REAL-TIME MUSIC GENERATION MODEL BASED ON BIOMETRIC SENSORS AVAILABLE ON WEARABLE SMART DEVICES
A research paper submitted in partial fulfillment of the requirements for completion of
Science and Engineering Inquiry
BANCROFT SCHOOL
Worcester, Massachusetts
TABLE OF CONTENTS
INTRODUCTION
Context of the Study
Music has already become one of the most important and necessary parts of our daily life, and sometimes our mood can be either reflected by the music or affected by it. With the increasing of stresses from the society and our daily life, more and more people started to choose to listen to music for entertainment and stress releasing, and there is biological and medical evidence that people response to different types of music under different situation does help release our stress and affect ourselves biologically (Thoma et al., 2013).
Also, more and more people in the United States have a smart wearable device with them. In 2023, about 44% of Americans own a smart wearable device that can track their health and biometric data (Nagappan et al., 2024). In 2024, this number increased to about 50% (Keller, 2024). With the improving availability of smart wearable devices, people can access their biometric data more easily, and also make the development of applications that rely on people’s biometric data more easily. These apps can help users have a better sense of their health conditions, and also help them improve their life quality.
With this, an app can be created that collects users’ biometric data from sensors provided by the smart watches to read and analyze users’ different moods, and generate music for the users in response to their moods of users. There are already apps that do a similar thing, but instead of generating music, they are using existing music and recommending it to the users in response to their mood (Moodify – Emotion-Based Music Recommendation App, 2025).
There are several benefits to doing this project: First, there is no need to worry about the amount of music that can be used and the workload of classifying that music. Since in this project, all music provided to the users is generated by the app itself. Also, this algorithm will mainly use music theory for generation. Hence, there should be no need for a huge data set and performance to train the generation model and use it for generating music, which allows users with low-end or even “potato” devices to generate the music they want.
Focus Statement/Question
Can real-time biometric data be used to generate enjoyable music that responds to the user’s emotions and physical movement?
BACKGROUNDn
Basic Terms
and Definitions for Music Features Description
Before digging deeper into the other concepts, several concepts and their definitions need to be clarified. Several key terms are used to describe the characteristics of a piece of music, which is also known as the music features or cues. The mode of a music is also known as the scale of the music, which describes a combination of notes with specific spacing between them (Wikipedia Contributors, 2023). The dynamics of a music describe the loudness and softness of the piece of music (Wikipedia Contributors, 2024). The articulation describes how each note should be played within a piece of music. Here are several different articulations: Tenuto, Marcato, Staccato, and Legato. The detailed definitions of these terms are below:
- Tenuto requires holding the note to its full length or even longer, or playing the note a little bit louder.
- Marcato requires a note or a chord to be played more forcefully than the other notes.
- Staccato denotes that a note will be played in a shortened duration
- Legato denotes that notes should be played smoothly and connected (Wikipedia Contributors, 2025)
The Timbre of a music describes the color, texture, and quality of the music that distinguishes this piece of music from other pieces (Timbre, 2020), and the Register of a music describes the range of pitches that an instrument or voice can produce. Registers are usually classified into high register, middle register, and low register (Register, 2024). These music features will be used as the generation baseline in the music generation phase, where the model will generate music according to the available music features.
Usages of Biometric Sensors Available for Smart Wearing Devices for Detection and Analysis
Biometric Sensors that are available on smart wearable devices are sufficient for emotion and mood monitoring and prediction. Research has already shown that daily wearable devices can help to recognize different emotions using biometric signals and data like electrodermal activity (EDA) and electrocardiogram (ECG), where EDA can be used to detect the triggers of different emotions, and ECG can be used to classify different triggers accurately (Arabian et al., 2023). Also, even only with ECG sensors and their data, it is still possible to predict users’ emotions and moods accurately. Different features of the ECG data can be used for analysis, including heart rate variability, R-R interval time, which indicates the time between the two successful R peaks, mean and standard deviation of heart rate, and entropy and irregularity of ECG data (Sayed Ismail et al., 2024). ECG sensors are generally available in nowadays smart wearable devices, and this makes mood analysis possible across different devices and easily accessible.
However, limitations still exist in using biometric data like ECG for mood analysis and prediction. During the model training process, the dataset size is usually small and limited, which causes inaccurate prediction results because of the limited data used for training. Also, different individuals sometimes have different psychological and biological responses to different events and moods in their daily life, which also increases the inaccuracy of prediction. All of those non-controllable factors bring challenges to the mood prediction based on biometric data (Saganowski et al., 2019).
The Expressions of Emotions in Music with Different Music Features
Different music represents different emotions and moods, and the expression of emotions is deeply tight to music features. Here are 6 primary music features that will be considered and used during the generation process: mode, tempo (the speed of the music), dynamics, articulation, timbre, and register. Research already indicates that the 6 music features above show a linear relationship with the emotion expressed, as shown in Table 1:
Table 1. Music Features and Their Relation with Emotion
Music Features | Variation | Related Emotions / Moods |
Scales | Major | Positive, happy |
Minor | Negative, sad | |
Tempo | Faster | Excitement, movement |
Slower | Calm, silence | |
Registers | High | Brightness, happiness |
Low | Darkness, sadness | |
Dynamics | High | Energetic |
Low | Calm | |
Articulation | Legato | Peaceful |
Staccato | Lively |
Table 1 shows the different variations of 5 example music features, and their relation with emotions or moods expressed.
With this linear relationship between the moods and music features (Eerola et al., 2013), we can easily classify the different emotions and moods into different specific music features, and generate music based on those music features.
Also, the arousal and the valence of music are the other two key factors that will be considered during the generation phase. The arousal of a music represents the biological or psychological reaction strength to the music, and the valence represents the positive or negative feelings that the person has to the music (Kim, 2023). Different emotions will be classified into different areas on a coordinate system constructed with valence and arousal of the music, and each area will also be related to different specific music features. This will allow the model to generate music using accurate music features based on users’ emotions and moods.
For this model, all music generated should be more Lo-Fi and ambient, because Lo-Fi and ambient music will not heavily influence people’s attention when they are focusing on something, and also Lo-Fi and ambient music can be used to reduce people’s anxiety (Melanie Pius Dsouza et al., 2024), which in this case this is aligned with the overall expectation of this project.
Related Tools, Frameworks, and Models can be Used for Music Generation, Composing, and App Development
Several different frameworks and tools will be used during the generation process or processes of this research. Librosa is a Python library that will be used for audio feature extraction (McFee et al., 2015). This will be used when collecting users’ satisfaction with different combinations of music features. Librosa will also be used to verify that the generation result is within the expectation, which means the music features extracted from the result should correspond to the classification standards.
Tone.js is a JavaScript library that will be used for composing music during the generation phase. Tone.js provides tools and utilities for creating and composing music just like how people operate a digital audio workstation (DAW), including basic oscillator and synthesizer support, MIDI signal processing, sample processing, etc. After all the music data is generated, it will be applied to Tone.js and implemented those data into a playable music.
Ionic Framework is a mobile development framework that allows developers to develop cross-platform mobile applications using web technologies (Ionic Framework, 2021). Ionic also integrates several native app features that allow developers to use native-level APIs like notifications, pop-ups, and hardware control under the web environment. Using this framework allows us to develop the applications we need on time because web technologies are easier to start with. Also, using the Ionic Framework can integrate Tone.js directly into our applications because both of them use web technologies.
K-nearest-neighbor algorithm is a supervised learning method (each input corresponds to an output, which unsupervised learning focuses on finding patterns from data) that will classify a datapoint into its nearest neighbor among different data clusters (Wikipedia Contributors, 2019). This algorithm will be used during the mood prediction model, which we will cluster collected biometric data into different mood groups, and moods can be predicted by grouping the new biometric datapoint into the closest mood group using the K-nearest-neighbors algorithm.
Applications for the Emotion-Responsive Music Generation Model
This project can be used in several different areas and applications. Emotion-responsive music generation can be used to help people relieve their stress in a variety of situations, and this can also help people manage their moods and maintain their mental health in a positive situation in a very adaptable and personal way (Hides et al., 2019). Plus, an emotion-responsive music generation model can also be used in mental therapies for people who need this for daily mental therapy. This allows people to get music therapy treatments anywhere and anytime, and allows patients to have a personalized treatment plan and method (Wang et al., 2023).
MATERIALS AND METHODS
Phase 1: Melody Generation Algorithm Design and Development
In this phase, a music generation model will be designed and developed. The music generation model will choose the musical instruments needed, melodies, and rhythms according to the music features parameters provided to the generation model based on users’ emotions. In the end, an updated range of music features in different moods will be decided according to users’ feedback from the initial generation results.
The following 16 moods shown in Table 2 will be used during the generation process, and the mood prediction model will also provide keywords from this list to the generation model. Also, this table provides the initial range for each music feature for each mood:
Table 2. List of Emotions Keywords and Their Corresponding Initial Music Features Value Range
Mood / Emotion | Scale | Register (Brightness) (Hz) | Tempo (BPM) | Dynamics (Loudness) (Hz) |
Happy | All Major Scales | 500-2000 | 120-160 | 400-1200 |
Excited | All Major Scales | 600-2000 | 130-160 | 600-1200 |
Fun | All Major Scales | 500-1800 | 120-150 | 500-1100 |
Cheerful | All Major Scales | 500-1500 | 110-140 | 400-1000 |
Calm | All Major Scales | 200-600 | 60-80 | 200-600 |
Focused | All Major Scales | 300-800 | 70-90 | 300-700 |
Chill | All Major Scales | 250-700 | 65-85 | 250-600 |
Nice | All Major Scales | 300-800 | 60-100 | 300-700 |
Mad | All Minor Scales | 400-1600 | 120-160 | 800-1500 |
Anxious | All Minor Scales | 400-1500 | 110-150 | 600-1300 |
Stressed | All Minor Scales | 500-1600 | 120-150 | 700-1400 |
Annoyed | All Minor Scales | 450-1400 | 110-140 | 600-1200 |
Sad | All Minor Scales | 100-500 | 40-70 | 100-400 |
Tired | All Minor Scales | 150-500 | 45-70 | 150-400 |
Lonely | All Minor Scales | 100-400 | 40-60 | 100-300 |
Bored | All Minor Scales | 150-600 | 50-80 | 150-500 |
Table 2 shows the 16 mood keywords that will be used during the mood identification and music generation. The initial value range and options for each of the music features are provided as well, these ranges are subject to change according to the user survey.
With the keywords decided, a bare-bones rhythm and melody generator will be developed. The generator will use the mood keyword and its corresponding music features range as parameters for generation. Because this generating model mainly relies on music theories, the model is able to generate rhythm and melody lines with one starting point, which is provided by the parameters, and continues generating rhythms and melodies based on the patterns existing in music theory and previously generated content. With all of the music features decided, the chord progression generator will start to generate overall chord progressions for the song, which will indicate the chord in one generation unit and its duration.
After the music features are input into the model and chord progressions are decided. The model will first decide which musical instruments will be used. The combination of instruments may be varied based on different emotions, scales, and target music style, but the combination of instruments must fulfill the following criteria:
- There must be one lead, one bass, and one key or pad.
- Other instruments and synthesizers can be added to balance the volume on each frequency
- At most 3 decorative sound effects instruments can be added
- The model should use at most 10 instruments
For each of the instruments, a melody and rhythm generator will be applied and start to generate notes with rhythm based on the type of instrument, and apply those notes to the instruments as MIDI signals.
After melodies and rhythms are generated for each instrument, Tone.js will start to play back the generated results and stream them to users. As Tone.js plays, the generator will keep adding new melodies to ensure the music is continuous, unless the mood changes
After the construction of the music generation model, several different short clips (around 30 seconds to 1 minute) of music for each mood tag indicated in Table 2 will be generated. These music clips will be evaluated for users’ satisfaction with the generated music. See hypothetical data in Table 6. New ranges of music features for each mood tag will be decided according to the user’s satisfaction data and applied to the generation model for the production environment. A visual representation of the overall music generation pipeline is demonstrated below:
Figure 1. A Visual Representation of the Music Generation Model Pipeline
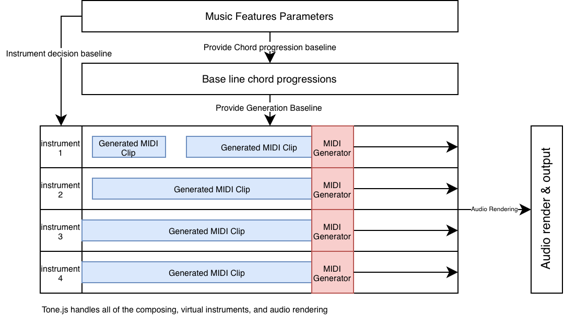
Figure 1 describes the overall structure of the music generation model, and also presents the workflow and pipeline for the model to generate music
Phase 2: Biometric Data Collection & Analysis with Mood Prediction Model
During this phase, a simple app to constantly collect users’ ECG and step data will be developed. After the user approves the app to collect its biometric data, the app will automatically record the ECG data, step number, and step increment from the last data point every 30 minutes. At each checkpoint, the app will also prompt the user to identify their current mood and emotion. See Table 4 for hypothetical data.
Based on the biometric data and emotion data collected, the different ECG features like heart rate and step numbers will be verified to make sure that they have significant differences across different moods. With the verified features and data, they will be clustered into different data groups, and each group will be labeled with a specific mood or emotion. After a new data point is entered, a simple K-nearest-neighbors algorithm will be performed to classify this data point into a data cluster to predict the mood. See Figure 3 for hypothetical clustered data.
After the data clustering, the app will be used to collect the user’s biometric data for another round. In this second round, the model-predicted mood will also be recorded to validate the prediction accuracy of the model. The data collected will be recorded in Table 5. This will be evaluated with a confusion matrix shown in Figure 4 in the Results and Analysis section. Those newly collected data points will also be added to the data clusters to improve the prediction accuracy.
Phase 3: Overall App Development and Performance Benchmarking
Here are two solutions for the development of this application:
- All-in-one application
- Web-based application
For an All-in-one application, both the mood-prediction model and the music generation model will be integrated into a single application. This allows users to generate music without the need for an Internet connection. However, this also means a larger app size and higher requirements for users’ devices.
For a web-based application, the client app will only have the mood prediction model embedded. All of the processes of biometric data will happen locally, and the application will only send predicted moods to the server running the music generation model. All music generation will happen in the cloud, and the server will stream back the audio to the client side. This significantly decreases the performance requirement for users’ devices, and also occupies smaller storage space. But this requires the users to have a reliable Internet connection to use this application.
The reason for two solutions is that Tone.js requires working in a Node.js environment, which is a web technology. Integrating Tone.js into the Ionic application is simple because both of them are based on JavaScript, but the reliability of the Ionic plugin to access health data from users’ phones and smart wearables needs to be tested. If the plugin is not working as expected, another native app development framework will be used to develop the client-side application to access users’ health data. In this situation, an all-in-one application is not realistic, and a web-based application will be developed.
After the app is developed, a generation benchmark will be performed under various hardware and operating systems. The formula for calculating the benchmark score is shown below:
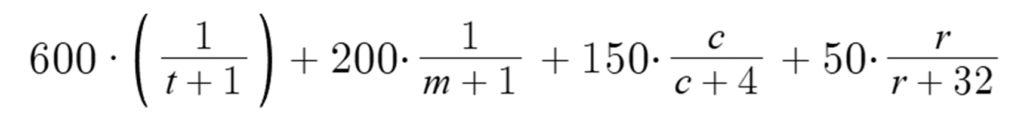
In this benchmark algorithm, t represents the generation time, m represents the amount of memory allocated to the application, c represents the number of CPU cores, and r represents the total amount of memory available on that specific hardware. This algorithm addresses the scaling difference and provides a more accurate representation of the actual improvement by applying diminishing marginal returns. Also, in this benchmarking algorithm, generation time and app allocated memory have larger weights than other factors because generation time and amount of RAM available are the two main factors that users can feel on the generation performance.
Safety Concerns
Users’ and experimenters’ data are sensitive and need to be protected. In this project and all related experiments, all data collected will be from experimenters with their consent and agreement. We will store all of the data securely so that it will not leak to the public. Also, no other data will be collected from other person and for any other purposes.
When the final application, features, and services are officially rolled out, a client privacy policy will be made to inform the users that the service will collect sensitive biometric data, and ensure the app and services are not abusing users’ data.
For the client-side application, all procedures and processes related to users’ biometric data will happen locally on users’ devices. The only data that will be sent to the online music generation service are the predicted moods keywords, and no users’ biometric data will be sent to any online services.
Timeline
Table 3 presents the timeline with estimated dates for this project.
Table 3. Estimated Timeline for this Project
Est. Dates | Tasks |
June 2025 | Asking advice from experts, improving details for the model designs, and procedures. Finalizing all procedures. |
July 2025 | Phase 1: Music generation model development and implementation. |
August 2025 | Phase 1: Asking for the user’s satisfaction on generation results, and optimizing the music features range for each mood tag. Finalize the music generation model. Phase 2: Biometric data collection app development, and first round of sample biometric data collection. Also, data will be clustered, and a simple prediction model will be developed. |
September 2025 | Phase 2: Second round of biometric data collection. Evaluate the mood prediction model’s accuracy. Finetuning and finalizing the mood prediction model. |
October 2025 | Phase 3: Overall application development (Client-side and server-side development), benchmark algorithm implementation, and gather benchmark scores across different devices to evaluate models’ performances. |
November 2025 | Data analysis + Paper write-up Beta version of the app will be released to the public. |
December 2025 | Data analysis + Paper write-up Stable version of the app will be released to the public. |
January 2026 | Paper write-up. The project will end in January 2026. |
Table 3 describes all tasks that need to be done and provides an estimated timeline with all important milestones and their dates for this project.
REFERENCES CITED
References
Arabian, H., Tamer Abdulbaki Alshirbaji, Schmid, R., Wagner-Hartl, V., J. Geoffrey Chase, & Knut Möller. (2023). Harnessing Wearable Devices for Emotional Intelligence: Therapeutic Applications in Digital Health. Sensors, 23(19), 8092–8092. https://doi.org/10.3390/s23198092
Eerola, T., Friberg, A., & Bresin, R. (2013). Emotional expression in music: contribution, linearity, and additivity of primary musical cues. Frontiers in Psychology, 4(487). https://doi.org/10.3389/fpsyg.2013.00487
Hides, L., Dingle, G., Quinn, C., Stoyanov, S. R., Zelenko, O., Tjondronegoro, D., Johnson, D., Cockshaw, W., & Kavanagh, D. J. (2019). Efficacy and Outcomes of a Music-Based Emotion Regulation Mobile App in Distressed Young People: Randomized Controlled Trial. JMIR MHealth and UHealth, 7(1), e11482. https://doi.org/10.2196/11482
Ionic Framework. (2021, October 5). GitHub. https://github.com/ionic-team/ionic-framework
Keller, J. (2024, September 9). Nearly Half of U.S. Households Own and Use Wearable Devices. Athletech News. https://athletechnews.com/u-s-households-wearable-devices/
Kim, A. J. (2023). Differential Effects of Musical Expression of Emotions and Psychological Distress on Subjective Appraisals and Emotional Responses to Music. Behavioral Sciences (2076-328X), 13(6), 491. https://doi.org/10.3390/bs13060491
McFee, B., Raffel, C., Liang, D., Ellis, D., McVicar, M., Battenberg, E., & Nieto, O. (2015). librosa: Audio and Music Signal Analysis in Python. Proceedings of the 14th Python in Science Conference. https://doi.org/10.25080/majora-7b98e3ed-003
Melanie Pius Dsouza, Shetty, A., Shwetha TS, Pooja Damodar, Asha Albuquerque Pai, Rebecca Joyline Mathias, D’Souza, S., & Neha Tanya Lewis. (2024). “I would want to listen to it as a medicine” – Lo-fi music and state anxiety, a mixed-methods pilot study on young adults. International Journal of Adolescence and Youth, 29(1). https://doi.org/10.1080/02673843.2024.2388787
Moodify – Emotion-Based Music Recommendation App. (2025). Moodify – Emotion-Based Music Recommendation App. https://moodify-emotion-music-app.netlify.app/
Nagappan, A., Knowles, M., & Krasniansky, A. (2024, August 5). Put a ring on it: Understanding consumers’ year-over-year wearable adoption patterns | Rock Health. Rock Health | We’re Powering the Future of Healthcare. Rock Health Is a Seed and Early-Stage Venture Fund That Supports Startups Building the next Generation of Technologies Transforming Healthcare. https://rockhealth.com/insights/put-a-ring-on-it-understanding-consumers-year-over-year-wearable-adoption-patterns
Register. (2024, December 28). Musical Dictionary | Music Terms Made Simple. https://www.musicaldictionary.com/glossary/register/
Saganowski, S., Dutkowiak, A., Dziadek, A., Dzieżyc, M., Komoszyńska, J., Michalska, W., Polak, A., Ujma, M., & Kazienko, P. (2019). Emotion Recognition Using Wearables: A Systematic Literature Review Work in progress. ArXiv (Cornell University). https://doi.org/10.48550/arxiv.1912.10528
Sayed Ismail, S. N. M., Ab. Aziz, N. A., Ibrahim, S. Z., & Mohamad, M. S. (2024). A systematic review of emotion recognition using cardio-based signals. ICT Express, 10(1), 156–183. https://doi.org/10.1016/j.icte.2023.09.001
Thoma, M. V., La Marca, R., Brönnimann, R., Finkel, L., Ehlert, U., & Nater, U. M. (2013). The effect of music on the human stress response. PLoS ONE, 8(8), e70156. https://doi.org/10.1371/journal.pone.0070156
Timbre. (2020, April 18). Wikipedia. https://en.wikipedia.org/wiki/Timbre
Tone.js. (n.d.). Tonejs.github.io. https://tonejs.github.io/
Wang, Z., Ma, L., Zhang, C., Han, B., Xu, Y., Wang, Y., Chen, X., Hong, H., Liu, W., Wu, X., & Zhang, K. (2023). REMAST: Real-time Emotion-based Music Arrangement with Soft Transition. ArXiv.org. https://arxiv.org/abs/2305.08029v3#
Wikipedia Contributors. (2019, March 19). k-nearest neighbors algorithm. Wikipedia; Wikimedia Foundation. https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Wikipedia Contributors. (2023, December 31). Mode (music). Wikipedia; Wikimedia Foundation. https://en.wikipedia.org/wiki/Mode_%28music%29
Wikipedia Contributors. (2024, October 15). Dynamics (music). Wikipedia; Wikimedia Foundation. https://en.wikipedia.org/wiki/Dynamics_%28music%29
Wikipedia Contributors. (2025, March 31). Articulation (music). Wikipedia; Wikimedia Foundation. https://en.wikipedia.org/wiki/Articulation_%28music%29