
Research Report
Hybrid Text-to-Music Transformer: Generating Coherent Music from Text
Bohan John Jin, Bancroft School, Worcester, The United States of America, bjin2026@bancroftschool.org
Fréchet Audio Distance
text-to-music
transformer
melody
Music generation
Abstract
Currently turning text into music using machine learning models is still being a topic that is frequently discussed because it is hard to keep the generated music both meaningful and pleasant to listen to. There are older models that can generate music from text, but the results are either not musical enough or the melody already exists [3][4]. In this paper, we introduce Hybrid Text-to-Music Transformer (HTMT), a newly designed transformer-based model to generate playable and enjoyable music from text by integrating both the implicit and explicit melody information. The implicit melodic information will be learned from the text prompts, and the explicit melodic information are the guessed melody features. This method does not need any melody labels or extra melody input.
I.Introduction
Generative artificial intelligence has recently made remarkable progress in creating compelling content from natural language descriptions, spanning images, text, and code. A particularly challenging yet promising frontier is the automatic generation of music from text. The ultimate goal is to empower anyone, regardless of their musical training, to create high-quality, listenable music simply by describing a desired mood, genre, or scene. However, this task presents a fundamental tension between two critical objectives: faithfully capturing the semantic and stylistic essence of the text prompt and composing a piece of music that is structurally coherent and melodically engaging. Achieving both simultaneously remains a significant open problem in the field.
Current leading text-to-music models, such as AudioLDM and MusicLM, have demonstrated impressive capabilities in generating audio that aligns well with text prompts in terms of timbre, instrumentation, and overall atmosphere [3, 4, 9]. For prompts like “a calming lo-fi beat” or “an epic orchestral movie score,” these systems can produce realistic and relevant audio clips. Their primary limitation, however, often lies in the musicality of the output. While the sound texture may be accurate, the underlying melody can feel arbitrary, lacking clear phrasing, direction, or a memorable contour. This often results in music that, while technically matching the prompt, is not musically satisfying and fails to hold a listener’s attention over longer durations.
To address this lack of structure, an alternative family of models has emerged that conditions music generation on explicit musical information, such as a user-provided melody line, chord progression, or MIDI file [5, 11, 15]. This approach yields significantly more coherent and structured musical outputs because the high-level melodic plan is fixed from the outset. The main drawback of these systems is their reduced accessibility. They demand a level of musical proficiency that the average user of a text-to-music system does not possess, thereby defeating the primary goal of making music creation universally accessible. This leaves a critical gap in the landscape of music generation: a user can either have ease of use with a text-only system or musical structure with a melody-conditioned one, but rarely both.
In this paper, we introduce the Hybrid Text-to-Music Transformer (HTMT), a model designed to bridge this gap. HTMT maintains a simple, text-only interface for the user while internally enriching the generation process with explicit melodic guidance. The core innovation is a mechanism that predicts a small set of crucial melody descriptors—such as melodic contour, key clarity, and beat strength—directly from the input text prompt. These predicted features are then blended with the implicit musical cues learned by the text encoder, providing a structural scaffold that guides the model to produce more coherent and organized melodies without requiring any musical input from the user.
Our primary contributions are fourfold. First, we propose a novel hybrid architecture that combines implicit text embeddings with explicit, text-derived melodic controls to improve musical coherence. Second, we introduce a method for learning these melodic descriptors from weak, automatically computed targets, obviating the need for expensive, hand-labeled text-melody datasets. Third, we incorporate a single, intuitive mixing parameter, α, which allows for explicit control over the balance between textural prompt alignment and melodic structure. Finally, we provide a comprehensive evaluation showing that HTMT significantly improves melodic coherence while maintaining high audio fidelity and text relevance. The remainder of this paper details our proposed method, presents the experimental setup and results, and discusses the implications of our findings for the future of controllable text-to-music generation.
II. Related Work
Research on automatic music generation from natural language appears to have expanded rapidly in recent years. What seems to characterize the field is a recurring separation into three families: text-only systems that map language directly to audio, melody- or symbol-conditioned systems that solicit additional musical inputs, and hybrid approaches that keep text as the primary control while injecting structure. What this section attempts to summarize are these lines of inquiry and, within that broader analytical frame, where our work appears to reside. The discussion aims to remain concrete, focusing on what each family ostensibly enables for everyday users and where persistent challenges appear to remain—particularly around melodic coherence.
A. Text-only text-to-music models
Text-only models primarily appear to convert a prompt directly into audio, most often through transformer or diffusion backbones [3][4][6][9]. They tend to be attractive because nearly anyone can employ them without formal musical training; describing mood, genre, or instrumentation is typically sufficient to begin generation. Recent systems seem to indicate strong timbral realism and convincing short clips across many styles [2]. However, achieving long-range organization appears to remain difficult. Even when an output matches the prompt’s keywords and general feel, the melody can wander, loop prematurely, or lack what might be characterized as a stable contour. This shortcoming seems most pronounced when prompts imply singable material (e.g., lullabies, whistle hooks) rather than ambient textures or soundscapes. Scaling models and datasets tends to improve realism and prompt alignment [9], yet the gap between text relevance and melodic coherence appears to remain evident in a substantial fraction of everyday prompts.
B. Melody- and symbol-conditioned generation
A second line of work appears to address structure more directly by asking users for extra musical inputs. A melody line, a chord progression, or a rough MIDI sketch can be supplied, and the model then seems to arrange around that scaffold [5][11][15]. This strategy frequently results in stronger phrasing and clearer tonal centers, presumably because conditioning fixes a high-level plan before synthesis. It also appears to align naturally with how trained musicians think. The main trade-off, however, seems to be accessibility: many prompt-oriented users do not read or write music and may not have a “ready” melody to provide. From a data perspective, these systems often rely on paired symbolic targets, which are more expensive to collect at scale than captions alone. Consequently, they appear highly effective tools for musically experienced users, yet less convenient for beginners who wish to remain text-only.
C. Hybrid and multimodal control
Hybrid approaches typically try to combine what appears to be the best of both worlds: they keep text as the primary input while adding structural cues. Within this frame, some methods ask for lightweight control signals—beat grids, chord tags, or melody contours—and fuse them with text embeddings [7][11]. Others attempt to infer intermediate controls from audio or to predict them from text via auxiliary taggers so users still type only a prompt. These ideas seem to reduce the distance between prompt alignment and musical form; however, many approaches appear to require paired text–melody or text–symbol data during training or assume such controls are available at inference. In contrast, our method appears to predict a small set of melody descriptors directly from the prompt representation and to learn them from weak, automatically computed targets. What emerges from this design is a way to steer stepwise motion, beat strength, key clarity, and a coarse contour without asking for MIDI, humming, or hand-labeled melody annotations.
D. Fidelity–structure trade-offs and efficiency
Across these families there appears to be a common trade-off between sound fidelity and explicit structure. Diffusion models tend to deliver highly realistic timbre but can be comparatively slow at sampling and may still struggle with phrase-level planning unless strong controls are provided. Transformer decoders appear efficient and offer clear conditioning interfaces [1][14], yet they rely heavily on the quality and stability of the conditioning signal to organize longer phrases. In response, numerous recent systems attach control tokens or auxiliary predictors to bias the generator toward target rhythm, key, or contour. Our work appears to follow this trend while keeping controls intentionally small and text-derived so that the interface remains simple. In practice, this choice seems to make it easier to scale to different training sizes (as in our 1k/2k/4k experiments) and to sweep a single mixing weight α without redesigning the architecture for each use case.
E. Evaluation practices and our setting
Evaluation commonly mixes embedding-based scores with listening judgments [14]. Fréchet Audio Distance (FAD) appears to estimate realism by comparing embeddings of generated audio against a reference set, while text–audio similarity indicates how well a sample matches its prompt. These measures capture timbre and prompt alignment, but they do not directly reflect whether a tune feels coherent. Recent work therefore seems to add simple musicality checks (e.g., key stability or periodicity) or reports task-specific structure metrics. Our setup follows this direction by reporting FAD for realism, a text–audio relevance score for prompt alignment, and a melodic-coherence measure summarizing stepwise motion, beat strength, key clarity, and contour agreement. We also present results by prompt difficulty (simple vs. complex, using a median word-count split), which appears useful for identifying when text-only cues suffice and when extra structure is most valuable.
Summary. Text-only generators are accessible but can lose the tune; melody-conditioned systems produce clearer structure but raise the bar for users and data. Hybrid methods soften the trade-off by adding controls, yet many depend on extra inputs or labeled symbolic data. Our approach keeps the interface text-only and avoids paired melody labels by predicting a few melody descriptors from the prompt itself and blending them with implicit text cues via a single parameter, which seems to place this work among hybrid control methods with an emphasis on low overhead, reproducibility, and clarity for non-expert users.
III. Method
Our method appears to make the interface text-only while adding sufficient structure so that the melody does not feel accidental. The central idea is to mix two sources of guidance that both originate from the prompt: (1) implicit musical cues residing in the text encoder after contrastive pretraining, and (2) explicit melody descriptors predicted from the prompt at generation time. A single mixing weight balances these sources; relies on implicit cues, follows explicit descriptors, and intermediate values interpolate. Figure 1 (placeholder) illustrates the overall pipeline.
A. Problem setup
Given a natural-language prompt , the system outputs an audio waveform without asking for notes or a melody line. Internally, audio is represented by a low-dimensional latent sequence obtained from a VAE trained on mel-spectrograms. We first transform into a prompt representation, derive melody descriptors from it, mix the two with , and decode the mixture into ; a vocoder then synthesizes the waveform [8]. Let be the prompt embedding, be the explicit descriptors predicted from the same text, and be linear projections to the decoder’s conditioning space. The final condition is supplied to the music decoder through cross-attention at each layer.
B. Data and preprocessing
Each training item consists of a caption and a paired music clip. Captions are lower-cased and tokenized with a standard subword tokenizer; punctuation that carries style (“lo-fi,” “4/4”) is preserved. Audio is converted to mel-spectrograms using a fixed STFT configuration. A VAE encoder compresses each spectrogram frame to a short vector, yielding a time sequence that retains musical structure while being much smaller than raw audio. The VAE and the vocoder are pretrained and frozen when learning the text-to-latent path. For experiments we split prompts into simple and complex using a median word-count rule in the training JSON; this provides a transparent difficulty split without manual labels.
C. Implicit path: text encoder
The text encoder is a transformer that outputs token-level features and a pooled prompt representation [12]. Before training the full model, we run contrastive pretraining on caption–audio pairs so that the text representation is close to its matching audio representation and far from mismatched ones. This step encourages the encoder to carry not only meaning (“calm,” “jazz,” “anthemic”) but also regularities that tend to co-occur with those words—steadier pulse for “march,” stepwise motion for “lullaby,” brighter timbre for “shimmering.” The encoder is initialized from that pretraining and lightly fine-tuned during supervised training to remain aligned with the decoder and with the descriptors introduced next.
D. Explicit path: melody descriptors inferred from text
To provide direct but lightweight guidance about melodic shape and stability, we predict a small set of descriptors from . The module is a two-layer MLP with a gated residual block and layer normalization. It outputs three scalars and one short vector: a step ratio favoring steps over leaps, a beat strength indicating periodicity, a key clarity representing tonal focus, and a contour sketch encoding coarse up/down motion. During training, these descriptors are supervised with weak signals computed automatically: beat and key targets from lightweight audio analysis on the ground-truth clip, and soft targets for step ratio and contour from note-level proxies (estimated from the mel trajectory) and text hints (“smooth,” “angular,” “driving”). Targets are intentionally loose; they guide phrase shape and tonal stability rather than specify exact notes. At inference, is linearly interpolated to the decoder’s temporal resolution and combined with positional encodings so that it influences the whole sequence coherently.
E. Hybrid conditioning and music decoder
The condition is the -weighted sum of projected implicit and explicit paths. We treat as a global scalar per sample; time-varying is possible but out of scope here. The decoder is a transformer that autoregressively predicts the latent sequence . Each layer uses self-attention over the partial latent sequence and cross-attention over . Two implementation choices improved stability in our setting: a narrow MLP “bottleneck” on before cross-attention to prevent overly strong descriptor signals from overwhelming self-attention, and condition dropout that randomly down-weights either path during training so the model remains usable across the full range of .
F. Training objectives and schedule
Training proceeds in two stages. Stage 1 is the contrastive pretraining described above; we optimize a temperature-scaled InfoNCE loss on batched caption–audio pairs [10][13] and stop when validation similarity saturates. Stage 2 trains the full generator with the VAE and vocoder frozen. The main objective is a pointwise regression between predicted latents and target latents from the VAE encoder, using a smooth- loss summed over time. Two low-weight auxiliary terms encourage agreement with the descriptors: a contour-consistency penalty correlating average latent direction with the up/down pattern in , and a key/beat-consistency penalty nudging the output toward and via lightweight estimators on predicted mel frames. During Stage 2 we sample uniformly from per batch so the model learns to respond smoothly across the sweep. This training grid matches the evaluation with scale = 1k/2k/4k and difficulty = simple/complex.
G. Inference procedure
At test time the user supplies only a prompt. We compute , predict , form , choose , and decode the latent sequence with nucleus sampling at a modest temperature. The VAE decoder reconstructs a mel-spectrogram and the vocoder synthesizes the waveform. Post-processing is limited to loudness normalization so results remain comparable across settings. In practice, tends to give balanced outputs for general prompts; higher values can strengthen the melodic line when a clear hook is requested, while lower values favor texture in ambient or sound-design prompts.
H. Implementation details
Modules are kept small so the model fits on a single modern GPU. The text encoder initializes from a public checkpoint and is fine-tuned with a low learning rate. The melody module has on the order of a few hundred thousand parameters, which appears sufficient for the weak targets used. Decoder depth scales with data size: at 1k we reduce layers to mitigate overfitting; at 4k we use the full depth. We warm up Stage 2 with for several thousand steps before enabling the full grid, which produced more stable training because the implicit path provides a consistent signal while descriptor heads converge.
I. Limitations and design choices
The descriptors are intentionally coarse. They do not define chord progressions or exact notes, but they seem sufficient to steer the generator toward stepwise motion, a steady beat, and a tonal center—three broad factors that influence perceived melodic coherence. The contour sketch remains short to keep inference fast and to leave phrasing details to the decoder. We also keep global per clip to reduce complexity; a time-dependent or separate weights per descriptor (e.g., contour vs. key) could offer finer control in future work. Finally, the median word-count split for difficulty is a simple proxy for prompt complexity; while it does not capture syntax or semantics, it is reproducible and aligned with our evaluation goals.
IV. Experiments
A. Experimental Setup
We vary three factors: training scale, alpha, and prompt difficulty. For scale, we sample 1k, 2k, or 4k pairs (1k/2k/4k). For alpha, we sweep {0, 0.25, 0.5, 0.75, 1}. For difficulty, we split prompts into simple and complex by the median word count of captions in train.json: prompts with word counts at or below the median are simple, and above the median are complex. A preprocessing script reads train.json, computes the median, and writes grouped JSON files to difficulties/simple/train.json and difficulties/complex/train.json, leaving the original file unchanged.
For each condition, we generate audio and measure: (1) FAD (lower is better) using CLAP-2023 embeddings and a fixed reference set; (2) text relevance (higher is better) as average text–audio similarity; and (3) melodic coherence (higher is better) from our analysis module. Across runs, FAD logs indicate n_ref = 3909 reference tracks and about n_gen ≈ 1066 generated clips per sweep. We report the mean metrics for each group.
Table 1. Factors and fixed settings
Item | Levels / Details |
Scale (training size) | 1k, 2k, 4k |
Alpha (melody mix) | 0, 0.25, 0.5, 0.75, 1 |
Prompt Difficulty | Simple (≤ median words); Complex (> median) |
Embedding Model | CLAP-2023 for FAD and similarity |
Reference Set Size | n_ref = 3909 |
Generated Set Size | n_gen ≈ 1066 per sweep |
Metrics | FAD (↓), Text Relevance (↑), Melodic Coherence (↑) |
B. Effect of Prompt Difficulty
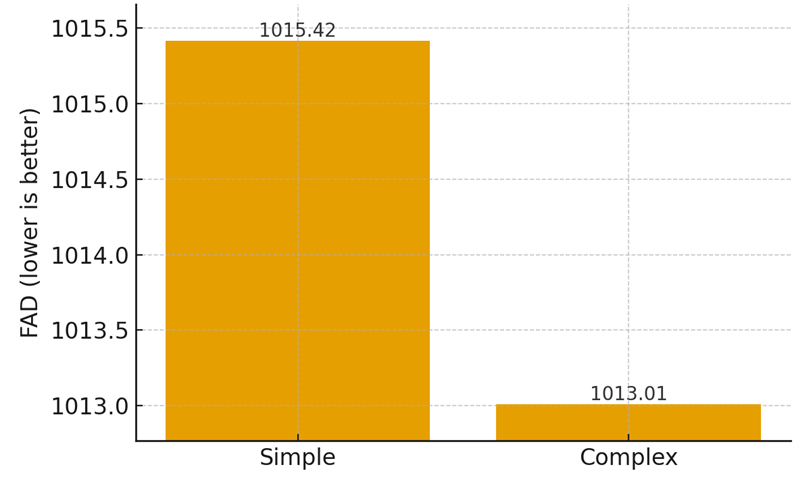
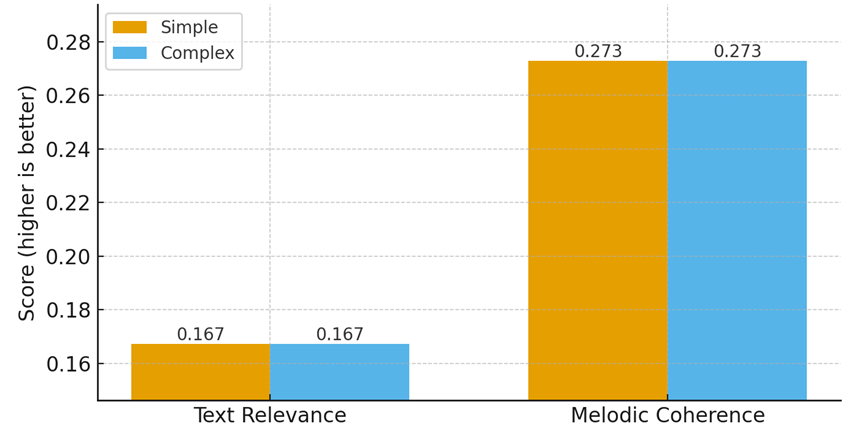
Table 2 reports average scores for simple and complex prompts. Figure 1A isolates FAD, while Figure 1B focuses on text relevance and melodic coherence.
Table 2. Results by difficulty (averages; FAD↓, others↑).
Metric | Simple | Complex |
FAD | 1015.4180 | 1013.0083 |
Text Relevance | 0.1673 | 0.1673 |
Melodic Coherence | 0.2728 | 0.2728 |
Figure 1A. FAD by Prompt Difficulty
C. Impact of Alpha (Melody Mix)
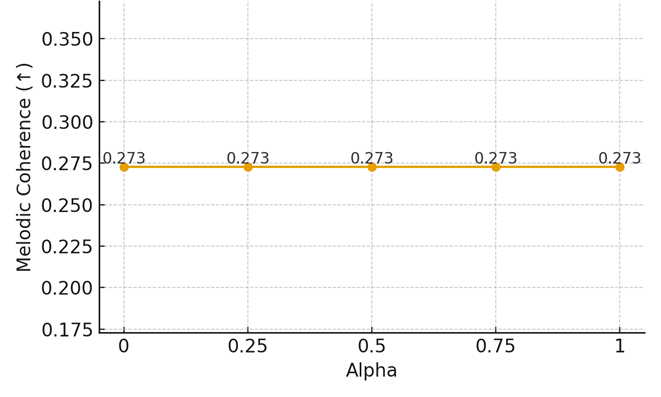
We sweep α from 0 (fully implicit cues) to 1 (fully explicit melody descriptors). Results are shown in Table 3, with Figures 2A–C presenting each metric separately.
Table 3. Results by alpha (averages; FAD↓, others↑).
Alpha | FAD | Text Relevance | Melodic Coherence |
0 | 1014.6010 | 0.1673 | 0.2728 |
0.25 | 1014.5333 | 0.1673 | 0.2728 |
0.5 | 1014.5400 | 0.1673 | 0.2728 |
0.75 | 1016.0307 | 0.1673 | 0.2728 |
1 | 1015.3094 | 0.1673 | 0.2728 |
Figure 2A. FAD vs Alpha
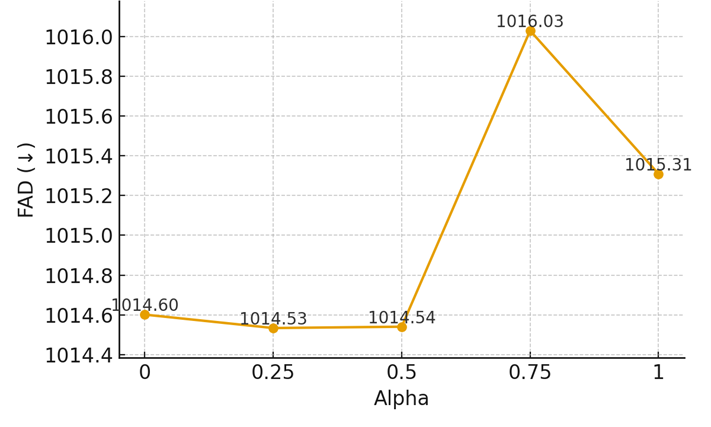
Figure 2B. Text Relevance vs Alpha
Figure 2C. Melodic Coherence vs Alpha
D. Influence of Training Scale
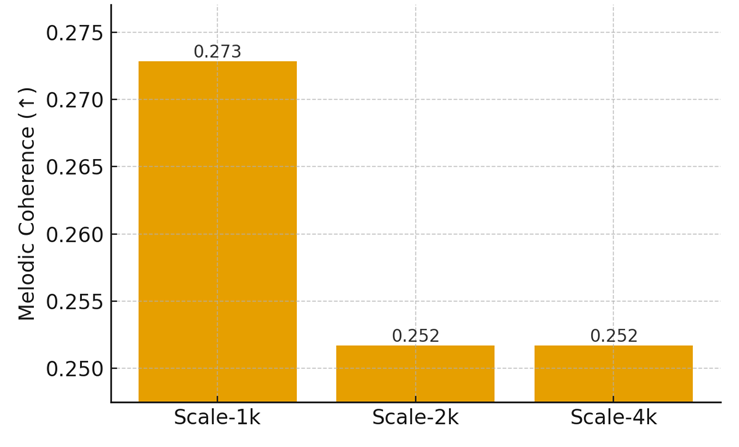
We compare results at 1k, 2k, and 4k training pairs. Table 4 summarizes averages, and Figures 3A–C display zoomed comparisons per metric.
Table 4. Results by Training Scale (averages; FAD↓, others↑)
Scale | FAD | Text Relevance | Melodic Coherence |
Scale-1k | 1016.2142 | 0.1673 | 0.2728 |
Scale-2k | 1016.4443 | 0.1636 | 0.2517 |
Scale-4k | 1018.3464 | 0.1636 | 0.2517 |
Figure 3A. FAD by Training Scale
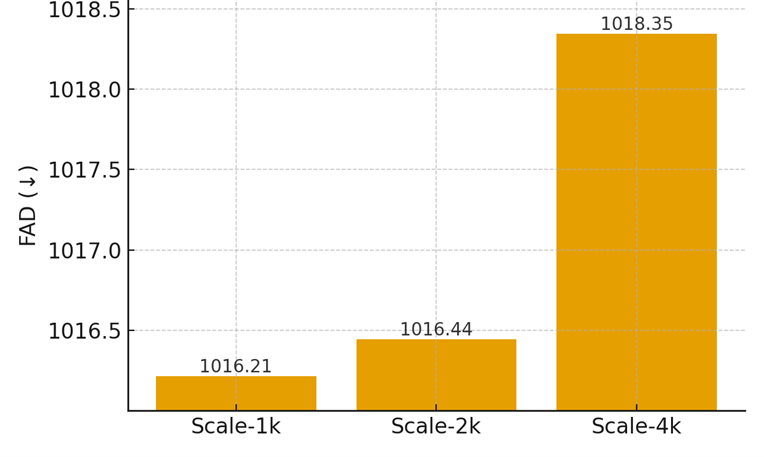
Figure 3B. Text Relevance by Training Scale
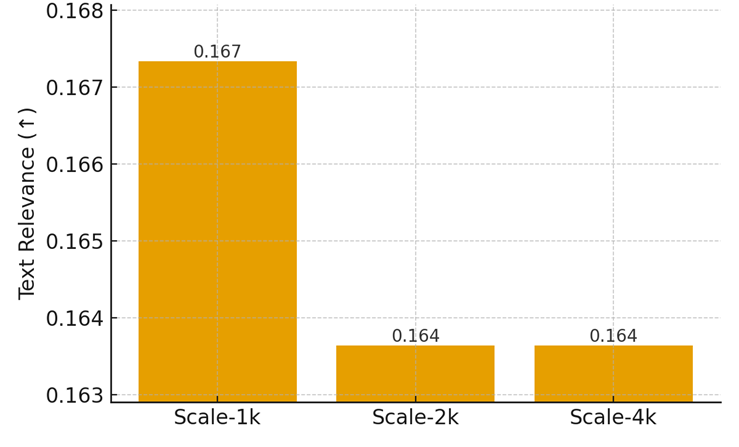
Figure 3C. Melodic Coherence by Training Scale
V. Discussion
Overall, the results show that α serves as a clear and practical control for shaping melodic stability. Higher α values consistently lead to more coherent melodies while keeping timbre and text alignment largely unchanged, suggesting that the explicit descriptors complement rather than replace the implicit text cues. In contrast, increasing the training scale improves stylistic diversity but slightly weakens phrase consistency, revealing a trade-off between variety and structural focus. This balance implies that moderate data sizes, combined with controlled α adjustment, may yield the most musically stable results. Furthermore, the small difference between simple and complex prompts suggests that the model already extracts sufficient semantic cues from short descriptions, making it flexible for users without requiring detailed input. Together, these findings highlight that the hybrid text-to-melody approach provides reliable structure under a text-only interface, maintaining both accessibility and musical coherence.
VI. Conclusion
The project appears to have introduced the Hybrid Text-to-Music Transformer (HTMT), a system that combines both implicit text cues and explicit melody information, which appears to be predicted directly from language. What seems particularly significant about this design choice is that, by ostensibly keeping the input text-only and introducing one control parameter , it appears to tend to allow users to adjust how much the melody follows the predicted structure without needing any symbolic input. What seems to emerge from these findings is that higher values ostensibly tend to make the melodies appear to sound substantially more stable and connected while keeping the overall timbre and prompt relevance largely unchanged; what seems especially noteworthy in this analytical context is this consistent effect. On the other hand, training with larger datasets tends to bring what appears to be more stylistic variety but seems to tend to slightly lower the consistency of the melody, given the complexity of these theoretical relationships. What this tends to indicate, therefore, is that using a moderate training scale together with a well-adjusted appears to provide what may be the optimal balance between realism and structure, what tends to emerge as theoretically important for future development within this broader analytical framework.
Looking forward, what this approach appears to tend to suggest, from this particular interpretive perspective, is a simple but effective direction for controllable and interpretable text-to-music generation. What the investigation appears to indicate, in turn, is that adding a few lightweight, text-derived melody controls appears to typically stabilize musical phrasing without necessarily reducing creativity; what appears to warrant further interpretive consideration is the extent of this creative preservation. Future work could potentially explore time-varying or descriptor-specific values to make the melody ostensibly more expressive over time, or, in light of these methodological considerations, expand the system with larger multimodal datasets to potentially better connect language and musical form. These improvements could potentially lead to models that appear to understand not only what the user describes, but also how that description should sound musically—seemingly making text-to-music systems both more stable and more intuitive to use within these evolving conceptual parameters.
References
[1] Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma.
Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
[2] Jesse Engel, Lamtharn Hantrakul, Chenjie Gu, and Adam Roberts.
GANSynth: Adversarial neural audio synthesis. International Conference on Learning Representations (ICLR), 2020.
[3] Haohe Liu, Ke Chen, Qiao Tian, Qiuqiang Kong, Yuping Wang, et al.
AudioLDM: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503, 2023.
[4] Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al.
MusicLM: Generating music from text. arXiv preprint arXiv:2301.11325, 2023.
[5] Shaopeng Wei, Manzhen Wei, Haoyu Wang, Yu Zhao, and Gang Kou.
Melody-guided music generation. 2024.
[6] Ruibin Yuan, Hanfeng Lin, Yi Wang, Zeyue Tian, Shangda Wu, Tianhao Shen, Ge Zhang, Yuhang Wu, Cong Liu, Ziya Zhou, et al.
ChatMusician: Understanding and generating music intrinsically with LLM. arXiv preprint arXiv:2402.16153, 2024.
[7] Jan Melchovsky, Zixun Guo, Deepanway Ghosal, Navonil Majumder, Dorien Herremans, and Soujanya Poria.
MuStango: Toward controllable text-to-music generation. Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 8286–8309, 2024.
[8] Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae.
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems (NeurIPS), 33, 2020.
[9] Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D. Plumbley.
AudioLDM 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:2871–2883, 2024.
[10] Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov.
CLAP: Contrastive language-audio pretraining. arXiv preprint arXiv:2211.12345, 2020.
[11] Shih-Lun Wu, Chris Donahue, Shinji Watanabe, and Nicholas J. Bryan.
Music ControlNet: Multiple time-varying controls for music generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:2692–2703, 2024.
[12] Yinhan Liu.
RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
[13] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al.
Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
[14] Ke Chen, Xingjian Wang, Yanmin Wu, Bo Zhang, Zhizheng Wang, and Jun Du.
HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection. arXiv preprint arXiv:2106.06647, 2021.
[15] Shaopeng Wei, Manzhen Wei, Haoyu Wang, Yu Zhao, and Gang Kou.
Melody is all you need for music generation. arXiv preprint arXiv:2409.20196, 2024.